入坑cs231n卷积神经网络入门,前期用到的都是python做assignment,主要用到numpy,scipy等数学工具,但是由于不太熟悉这些Python工具,所以遇到的问题都记录下来,以待研究。
标签(空格分隔): Python
Python 入门
Python是一种高级的,动态类型的的多范型编程语言。可以通过少数几行代码就表达出很有想象力的思想。
Python实现快速排序的算法的例子:
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr)/2]
left = [x for x in arr if x < pivot]
mid = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left)+mid+quicksort(right)
print quicksort([3,6,8,10,1,2,1])
# Prints "[1, 1, 2, 3, 6, 8, 10]"
基本数据类型
基本上和其他编程语言差不多。
Python拥有一系列的基本数据类型,比如整型、浮点型、布尔型和字符串等。这些类型的使用方式和在其他语言中的使用方式是类似的。
NOTE: Python 没有 ++ – 操作。
| Python 也有布尔逻辑运算,但不是 | && 符号,而是 or ,and, not 等英文单词。 |
Python 对于字符串对象支持很好,以前做数学建模有文本聚类分析就用了Python,不过当时只是匆匆看了下怎么使用,并没有深入去了解。
容器 Contaners
Python有以下几种容器类型:列表(lists)、字典(dictionaries)、集合(sets)和元组(tuples)。
个人觉得这个可以和Cpp的容器联系起来,是一种放基本数据类型的类型。
列表 List
List 是 Python中的数组。 可以改变长度 而且可以包含有不同类型元素。
list1 = [1,2,3,4]
list1.append(5)
print list1
#[1, 2, 3, 4, 5]
list1.append('foo')
print list1
#[1, 2, 3, 4, 5, 'foo']
x = list1.pop()
print x, list1
#foo [1, 2, 3, 4, 5]
切片 Slicing
为了一次性获取列表中的元素,Python提供了一种简洁的语法叫切片。其他语言可能取出容器中的元素要用到循环,我觉得切片就是取代了循环来获取元素,而且这种方法在Python中比循环效率要高。
nums = range(5)
print nums
print nums[2:4]
#[0, 1, 2, 3, 4]
#[2, 3] 取出了index从2到3的元素,左闭右开
print nums[2:] #从第二个取到最后一个[2, 3, 4]
print nums[:3] #从开始取到第n个,index为n-1 [0, 1, 2]
print nums[:-1] # 取到倒数第一个,右开区间
print nums[:] # 全部
nums[2:4] = [8, 9] # Assign a new sublist to a slice
print nums # Prints "[0, 1, 8, 9, 4]"
循环 Loops
animals = ['cat', 'dog', 'cow', 'monkey']
for animal in animals:
print animal
# Prints "cat", "dog", "monkey", each on its own line.
如果要获取index 可以用enumerate函数。
如果想要在循环体内访问每个元素的指针,可以使用内置的enumerate函数
animals = ['cat', 'dog', 'cow', 'monkey']
for index,animal in enumerate(animals):
print '#%d:%s' % (index+1, animal)# python 格式化输出
# Prints "#1: cat", "#2: dog", "#3: monkey", each on its own line
列表推导List comprehensions
如果要让一个列表中所有元素平方,用循环可以,用列表推导就很简洁。
nums = [1,2,3,4,5,6]
squares = [ x*x for x in nums]
print squares
#[1, 4, 9, 16, 25, 36]
#也可以包含条件,就像第一节里简洁的快速排序一样
squares = [x*x for x in nums if x % 2]
print squares
#[1, 9, 25] 只找奇数的
字典Dictionaries
字典用来储存(键, 值),有点像其他语言的Map
字典{ }, 列表[]
d = {'cat':'cute', 'dog':'furry'}
print d['cat'] #cute 根据键来 找 值 像数组吧。。
print 'cat' in d # Check if a dictionary has a given key; prints "True"
d['fish'] = 'wet' # Set an entry in a dictionary
print d['fish'] # Prints "wet"
# print d['monkey'] # KeyError: 'monkey' not a key of d
print d.get('monkey', 'N/A') # Get an element with a default; prints "N/A"
print d.get('fish', 'N/A') # Get an element with a default; prints "wet"
del d['fish'] # Remove an element from a dictionary
print d.get('fish', 'N/A') # "fish" is no longer a key; prints "N/A"
循环Loops:在字典中,用键来迭代更加容易。
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal in d: #字典中迭代的是键。。
legs = d[animal]
print 'A %s has %d legs' % (animal, legs)
# Prints "A person has 2 legs", "A spider has 8 legs", "A cat has 4 legs"
如果你想要访问键和对应的值,那就使用iteritems方法:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal, legs in d.iteritems():
print 'A %s has %d legs' % (animal, legs)
# Prints "A person has 2 legs", "A spider has 8 legs", "A cat has 4 legs"
字典推导Dictionary comprehensions:和列表推导类似,但是允许你方便地构建字典。
nums = [0, 1, 2, 3, 4]
even_num_to_square = {x: x ** 2 for x in nums if x % 2 == 0}
print even_num_to_square
# Prints "{0: 0, 2: 4, 4: 16}"
集合Sets
集合是独立的不同个体的无序集合。
set {} 也是用大括号
animals = {'cat', 'dog'}
print 'cat' in animals # Check if an element is in a set; prints "True"
print 'fish' in animals # prints "False"
animals.add('fish') # Add an element to a set 添加元素用add
print 'fish' in animals # Prints "True"
print len(animals) # Number of elements in a set; prints "3"
animals.add('cat') # Adding an element that is already in the set does nothing
print len(animals) # Prints "3"
animals.remove('cat') # Remove an element from a set#去掉元素用remove
print len(animals) # Prints "2"
集合也可以for 循环,但是是无序的,不能假设顺序。。。
animals = {'cat', 'dog', 'fish'}
for idx, animal in enumerate(animals):
print '#%d: %s' % (idx + 1, animal)
# Prints "#1: fish", "#2: dog", "#3: cat"
集合推导Set comprehensions:和字典推导一样,可以很方便地构建集合:
from math import sqrt
nums = {int(sqrt(x)) for x in range(30)}
print nums
# Prints "set([0, 1, 2, 3, 4, 5])"
nums.add(5)
print nums
nums.add(55)
print nums
#set([0, 1, 2, 3, 4, 5]) 因为已经有5了 所以不会加进去
#set([0, 1, 2, 3, 4, 5, 55])
#因为set是独立不同个体的集合,所以没有重复的元素。
元组Tuples
元祖这个概念是和其他编程语言都好像不同的了,算是一个新知识吧。 回顾一下: list = [1,2,3,4] dic = {1:2, 2:3, 3:4} set = {1,2,3,4,5} tuples = (1,2)
元祖是一个值的 有序 列表(不可改变)
从很多方面来说,元组和列表都很相似。和列表最重要的不同在于,元组可以在字典中用作键,还可以作为集合的元素,而列表不行。
d = {(x,x + 1) : x for x in range(5)}
print d
# {(0, 1): 0, (1, 2): 1, (3, 4): 3, (2, 3): 2, (4, 5): 4}
# d是一个字典,而它的键是 元祖
t = (3, 4) # Create a tuple
print type(t) # Prints "<type 'tuple'>"
print d[t] # Prints "3"
print d[(1, 2)] # Prints "1"
函数Functions
Python使用 def来定义函数:
def sign(x):
if x > 0:
return 'positive'
elif x < 0:
return 'negative'
else:
return 'zero'
for x in [-1, 0, 1]:
print sign(x)
# Prints "negative", "zero", "positive"
我们常常使用可选参数来定义函数:
def hello(name, loud=False):
if loud:
print 'HELLO, %s' % name.upper()
else:
print 'Hello, %s!' % name
hello('Bob') # Prints "Hello, Bob"
hello('Fred', loud=True) # Prints "HELLO, FRED!"
类Classes
Python对于类的定义是简单直接的:
class Greeter(object):
# Constructor
def __init__(self, name):
self.name = name # Create an instance variable
# Instance method
def greet(self, loud=False):
if loud:
print 'HELLO, %s!' % self.name.upper()
else:
print 'Hello, %s' % self.name
g = Greeter('Fred') # Construct an instance of the Greeter class
g.greet() # Call an instance method; prints "Hello, Fred"
g.greet(loud=True) # Call an instance method; prints "HELLO, FRED!"
Numpy
Numpy是Python中用于科学计算的核心库。它提供了高性能的多维数组对象,以及相关工具。
Numpy数组Arrays
import numpy as np
a = np.array([1, 2, 3]) # Create a rank 1 array
print type(a) # Prints "<type 'numpy.ndarray'>"
print a.shape # Prints "(3,)"
print a[0], a[1], a[2] # Prints "1 2 3"
a[0] = 5 # Change an element of the array
print a # Prints "[5, 2, 3]"
ab =np.array([[1,2,3]])
print ab.shape # Prints (1, 3)
print ab # Prints [[1 2 3]]
print ab.flatten() # Prints [1 2 3]
b = np.array([[1,2,3],[4,5,6]]) # Create a rank 2 array
print b # 显示一下矩阵b
print b.shape # Prints "(2, 3)"
print b[0, 0], b[0, 1], b[1, 0] # Prints "1 2 4"
Numpy还提供了很多其他创建数组的方法:
import numpy as np
a = np.zeros((2,2)) # Create an array of all zeros
print a # Prints "[[ 0. 0.]
# [ 0. 0.]]"
b = np.ones((1,2)) # Create an array of all ones
print b # Prints "[[ 1. 1.]]"
c = np.full((2,2), 7) # Create a constant array
print c # Prints "[[ 7. 7.]
# [ 7. 7.]]"
d = np.eye(2) # Create a 2x2 identity matrix
print d # Prints "[[ 1. 0.]
# [ 0. 1.]]"
e = np.random.random((2,2)) # Create an array filled with random values
print e # Might print "[[ 0.91940167 0.08143941]
# [ 0.68744134 0.87236687]]"
Numpy 访问数组
Numpy提供了多种访问数组的方法。
切片:和Python列表类似,numpy数组可以使用切片语法。因为数组可以是多维的,所以你必须为每个维度指定好切片。
import numpy as np
# Create the following rank 2 array with shape (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
# Use slicing to pull out the subarray consisting of the first 2 rows
# and columns 1 and 2; b is the following array of shape (2, 2):
# [[2 3]
# [6 7]]
b = a[:2, 1:3]
# A slice of an array is a view into the same data, so modifying it
# will modify the original array.
# 切片之后的数组还是指向原来的数组, 相当于一个部分引用
print a[0, 1] # Prints "2"
b[0, 0] = 77 # b[0, 0] is the same piece of data as a[0, 1]
print a[0, 1] # Prints "77"
数据类型
每个Numpy数组都是数据类型相同的元素组成的网格。Numpy提供了很多的数据类型用于创建数组。当你创建数组的时候,Numpy会尝试猜测数组的数据类型,你也可以通过参数直接指定数据类型,例子如下:
import numpy as np
x = np.array([1, 2]) # Let numpy choose the datatype
print x.dtype # Prints "int64"
x = np.array([1.0, 2.0]) # Let numpy choose the datatype
print x.dtype # Prints "float64"
x = np.array([1, 2], dtype=np.int64) # Force a particular datatype
print x.dtype # Prints "int64"
数组计算
重点来了,学会numpy的数组计算可以在Python下写出 Vectorized code.
np的数组计算,基本的+,-,*,/,sqrt都是Elementwise的。
对应的numpy函数是np.add(), np.subtract(), np.multiply(), np.divide(), np.sqrt()
基本数学计算函数会对数组中元素逐个进行计算,既可以利用操作符重载,也可以使用函数方式:
import numpy as np
x = np.array([[1,2],[3,4]], dtype=np.float64)
y = np.array([[5,6],[7,8]], dtype=np.float64)
# Elementwise sum; both produce the array
# [[ 6.0 8.0]
# [10.0 12.0]]
print x + y
print np.add(x, y)
# Elementwise difference; both produce the array
# [[-4.0 -4.0]
# [-4.0 -4.0]]
print x - y
print np.subtract(x, y)
# Elementwise product; both produce the array
# [[ 5.0 12.0]
# [21.0 32.0]]
print x * y
print np.multiply(x, y)
# Elementwise division; both produce the array
# [[ 0.2 0.33333333]
# [ 0.42857143 0.5 ]]
print x / y
print np.divide(x, y)
# Elementwise square root; produces the array
# [[ 1. 1.41421356]
# [ 1.73205081 2. ]]
print np.sqrt(x)
numpy基本函数
np.square()求平方np.sum()求和np.sqrt()求开方argsort()从小到大排序,返回排序前对应的索引
import numpy as np
x=np.array([1,4,3,-1,6,9])
x.argsort()
输出结果是:y=array([3,0,2,1,4,5])
import numpy as np
x = np.array([[1,2],[3,4]])
print np.sum(x) # Compute sum of all elements; prints "10"
print np.sum(x, axis=0) # Compute sum of each column; prints "[4 6]"
print np.sum(x, axis=1) # Compute sum of each row; prints "[3 7]"
从函数名字可以知道这是对一个数组进行排序,可以从结果上看到,这是一种 将原数组排序之后,提取元素在原数组中的索引 的排序算法,即 将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y 最小的为原数组index = 3的元素,最大的是原数组中index = 5的元素。
x.argsort()[:k] 表示把排在前k的索引提取出来。
np.bincount()返回的bin数组大小比实参数组x中最大值大1,每个bin给出了它的索引值在x中出现的次数得到每个index出现的次数,即每个元素出现的次数。x = np.array([1,5,6,7,5,5]) np.bincount(x) # output # array([0, 1, 0, 0, 0, 3, 1, 1])np.argmax()返回最大数的索引axis = 0andaxis = 1区别
axis=0代表往跨行(down),而axis=1代表跨列(across),作为方法动作的副词 官方解释:轴用来为超过一维的数组定义的属性,二维数据拥有两个轴:第0轴沿着行的垂直往下,第1轴沿着列的方向水平延伸.
- 使用0值表示沿着每一列或行标签\索引值向下执行方法
- 使用1值表示沿着每一行或者列标签模向执行对应的方法
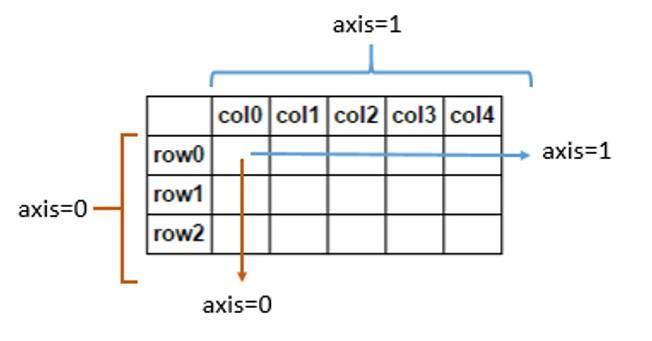
np.array_split()把 narray 分成 x 份
x = np.arange(9)
np.array_split(x,3)
# [array([0, 1, 2]), array([3, 4, 5]), array([6, 7, 8])]
广播 Broadcasting
这个也是numpy强有力的机制之一,它可以让不同大小的矩阵进行数学计算。
我们常常会有一个小的矩阵和一个大的矩阵,然后我们会需要用小的矩阵对大的矩阵做一些计算。
举个例子,如果我们想要把一个向量加到矩阵的每一行,我们可以这样做:
import numpy as np
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = np.empty_like(x) # Create an empty matrix with the same shape as x
# Add the vector v to each row of the matrix x with an explicit loop
for i in range(4):
y[i, :] = x[i, :] + v
# Now y is the following
# [[ 2 2 4]
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]
print y
这样是行得通的,但是当x矩阵非常大,利用循环来计算就会变得很慢很慢。我们可以换一种思路:
import numpy as np
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
vv = np.tile(v, (4, 1)) # Stack 4 copies of v on top of each other
print vv # Prints "[[1 0 1]
# [1 0 1]
# [1 0 1]
# [1 0 1]]"
y = x + vv # Add x and vv elementwise
print y # Prints "[[ 2 2 4
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]"
利用 广播 机制,可以直接运算
import numpy as np
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = x + v # Add v to each row of x using broadcasting
print y # Prints "[[ 2 2 4]
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]"
对两个数组使用广播机制要遵守下列规则:
- 如果数组的秩不同,使用1来将秩较小的数组进行扩展,直到两个数组的尺寸的长度都一样。
- 如果两个数组在某个维度上的长度是一样的,或者其中一个数组在该维度上长度为1,那么我们就说这两个数组在该维度上是相容的。
- 如果两个数组在所有维度上都是相容的,他们就能使用广播。
- 如果两个输入数组的尺寸不同,那么注意其中较大的那个尺寸。因为广播之后,两个数组的尺寸将和那个较大的尺寸一样。
- 在任何一个维度上,如果一个数组的长度为1,另一个数组长度大于1,那么在该维度上,就好像是对第一个数组进行了复制。
译者注:强烈推荐阅读文档中的例子。
解释
文档
Logs:
- 2018-02-16 入坑
- 2018-04-12 补充详细内容